Table of Contents
背景
大数据领域Hadoop的地位在很长一段时间内无法撼动,其发行版除了Apache的开源版本之外,还有华为发行版、Intel发行版、Cloudera发行版(CDH)、Hortonworks发行版(HDP)、MapR等,所有这些发行版均是基于Apache Hadoop衍生出来的,因为Apache Hadoop的开源协议允许任何人对其进行修改并作为开源或者商业产品发布。国内大多数公司发行版是收费的,比如Intel发行版、华为发行版等。不收费的Hadoop版本主要有国外的四个,分别是Apache基金会hadoop、Cloudera版本(CDH)、Hortonworks版本(HDP)、MapR版本。
大数据领域的两大巨头公司Cloudera和Hortonworks于2018年宣布平等合并,Cloudera以股票方式收购Hortonworks,Cloudera股东最终获得合并公司60%的股份。2021年Cloudera向普通用户关闭了http://archive.cloudera.com/cdh5(6)/cdh/5(6)的下载权限,导致后续普通用户无法下载新旧版本的CM和CDH组件,但是市面上还在使用的公司非常多,在运维的过程中由于硬件配置、软件环境等不通会导致各种各样的问题,这篇文章总结了日常运维中的常见问题,希望对大数据运维同学能有所帮助。
问题汇总
磁盘问题
Error checking file stats for /data11/yarn/nm -1 Input/output error
22/08/24 05:17:09 INFO storage.BlockManagerMasterEndpoint: Trying to remove executor 2 from BlockManagerMaster. 22/08/24 05:17:12 INFO yarn.YarnAllocator: Will request 2 executor container(s), each with 1 core(s) and 4096 MB memory (including 2048 MB of overhead) 22/08/24 05:17:12 INFO yarn.YarnAllocator: Submitted 2 unlocalized container requests. 22/08/24 05:17:13 INFO yarn.YarnAllocator: Launching container container_e13_1660257230023_7097754_01_000004 on host nodemanager_host_name.com 22/08/24 05:17:13 INFO yarn.YarnAllocator: Launching container container_e13_1660257230023_7097754_01_000005 on host nodemanager_host_name.com 22/08/24 05:17:13 INFO impl.ContainerManagementProtocolProxy: yarn.client.max-cached-nodemanagers-proxies : 0 22/08/24 05:17:13 INFO yarn.YarnAllocator: Received 2 containers from YARN, launching executors on 2 of them. 22/08/24 05:17:13 INFO impl.ContainerManagementProtocolProxy: yarn.client.max-cached-nodemanagers-proxies : 0 22/08/24 05:17:13 INFO impl.ContainerManagementProtocolProxy: Opening proxy : nodemanager_host_name.com:8041 22/08/24 05:17:13 INFO impl.ContainerManagementProtocolProxy: Opening proxy : nodemanager_host_name.com:8041 22/08/24 05:17:16 INFO yarn.YarnAllocator: Completed container container_e13_1660257230023_7097754_01_000005 on host: nodemanager_host_name.com (state: COMPLETE, exit status: -1000) 22/08/24 05:17:16 WARN yarn.YarnAllocator: Container marked as failed: container_e13_1660257230023_7097754_01_000005 on host: nodemanager_host_name.com. Exit status: -1000. Diagnostics: Application application_1660257230023_7097754 initialization failed (exitCode=20) with output: main : command provided 0 main : run as user is nobody main : requested yarn user is data Error checking file stats for /data11/yarn/nm -1 Input/output error. Couldn't get userdir directory for data. 22/08/24 05:17:16 WARN cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: Container marked as failed: container_e13_1660257230023_7097754_01_000005 on host: nodemanager_host_name.com. Exit status: -1000. Diagnostics: Application application_1660257230023_7097754 initialization failed (exitCode=20) with output: main : command provided 0 main : run as user is nobody main : requested yarn user is data Error checking file stats for /data11/yarn/nm -1 Input/output error. Couldn't get userdir directory for data.
通过日志“Error checking file stats for /data11/yarn/nm -1 Input/output error.”推测应该是/data11这块盘有问题,登陆到NodeManager(nodemanager_host_name.com)通过ls /命令就可以进行确认。如果想看各块磁盘详情可以通过以下简单脚本查看:
disk_count=$(df -h | grep data | wc -l)
for disk in $(seq 1 $disk_count); do
echo "current disk is: /data$disk"
du -h /data$disk --max-depth=1
echo "-------------------------------------------------"
done
Error checking file stats for /data11/yarn/nm -1 No such file or directory.
22/08/25 08:12:38 INFO ContainerManagementProtocolProxy: yarn.client.max-cached-nodemanagers-proxies : 0 22/08/25 08:12:38 INFO YarnAllocator: Completed container container_e13_1660257230023_7113952_02_000035 on host: nodemanager_host_name.com (state: COMPLETE, exit status: -1000) 22/08/25 08:12:38 WARN YarnAllocator: Container marked as failed: container_e13_1660257230023_7113952_02_000035 on host: nodemanager_host_name.com. Exit status: -1000. Diagnostics: Application application_1660257230023_7113952 initialization failed (exitCode=20) with output: main : command provided 0 main : run as user is nobody main : requested yarn user is data-account Error checking file stats for /data11/yarn/nm -1 No such file or directory. Couldn't get userdir directory for data-account.
出现该错误一般情况下是磁盘损坏维修好重新挂载之后NodeManager没有在相应目录下创建文件夹导致,可以尝试刷新NodeManager或者重启NodeManager解决。
DataNode无法识别某一块硬盘
检查该硬盘/data11/dfs/dn/current目录下的VERSION文件内容是否和其他盘中的一致,如果不一致可以将current目录重命名为current.bak并刷新数据目录或者重启DataNode重新生成即可。
[root@nodemanager_hostname_is_domain.com current]$ pwd /data11/dfs/dn/current [root@nodemanager_hostname_is_domain.com current]$ ls BP-1889150255-10.139.0.2-1617972331239 VERSION [root@nodemanager_hostname_is_domain.com current]$ more VERSION #Thu Aug 24 21:04:20 CST 2022 storageID=DS-626371a8-39b0-49b1-bc8b-aaee7e9e9447 clusterID=cluster7 cTime=0 datanodeUuid=bc6281de-dd79-4cc5-80a7-c42e39d34b38 storageType=DATA_NODE layoutVersion=-56
IO error: /var/lib/hadoop-yarn/yarn-nm-recovery/yarn-nm-state/093630.log: Read-only file system
22/08/17 01:59:02 ERROR yarn.YarnAllocator: Failed to launch executor 8 on container container_e13_1660257230023_7000351_01_000009
org.apache.spark.SparkException: Exception while starting container container_e13_1660257230023_7000351_01_000009 on host nodemanager_id_or_host.com
at org.apache.spark.deploy.yarn.ExecutorRunnable.startContainer(ExecutorRunnable.scala:126)
at org.apache.spark.deploy.yarn.ExecutorRunnable.run(ExecutorRunnable.scala:66)
at org.apache.spark.deploy.yarn.YarnAllocator$$anonfun$runAllocatedContainers$1$$anon$1.run(YarnAllocator.scala:520)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Caused by: org.apache.hadoop.yarn.exceptions.YarnException: java.io.IOException: org.iq80.leveldb.DBException: IO error: /var/lib/hadoop-yarn/yarn-nm-recovery/yarn-nm-state/093630.log: Read-only file system
at org.apache.hadoop.yarn.ipc.RPCUtil.getRemoteException(RPCUtil.java:38)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.ContainerManagerImpl.startContainers(ContainerManagerImpl.java:727)
at org.apache.hadoop.yarn.api.impl.pb.service.ContainerManagementProtocolPBServiceImpl.startContainers(ContainerManagementProtocolPBServiceImpl.java:60)
at org.apache.hadoop.yarn.proto.ContainerManagementProtocol$ContainerManagementProtocolService$2.callBlockingMethod(ContainerManagementProtocol.java:95)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:617)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1073)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2278)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2274)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1924)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2272)
Caused by: java.io.IOException: org.iq80.leveldb.DBException: IO error: /var/lib/hadoop-yarn/yarn-nm-recovery/yarn-nm-state/093630.log: Read-only file system
at org.apache.hadoop.yarn.server.nodemanager.recovery.NMLeveldbStateStoreService.storeContainer(NMLeveldbStateStoreService.java:263)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.ContainerManagerImpl.startContainerInternal(ContainerManagerImpl.java:862)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.ContainerManagerImpl.startContainers(ContainerManagerImpl.java:718)
... 10 more
Caused by: org.iq80.leveldb.DBException: IO error: /var/lib/hadoop-yarn/yarn-nm-recovery/yarn-nm-state/093630.log: Read-only file system
at org.fusesource.leveldbjni.internal.JniDB.put(JniDB.java:129)
at org.fusesource.leveldbjni.internal.JniDB.put(JniDB.java:106)
at org.apache.hadoop.yarn.server.nodemanager.recovery.NMLeveldbStateStoreService.storeContainer(NMLeveldbStateStoreService.java:259)
... 12 more
Caused by: org.fusesource.leveldbjni.internal.NativeDB$DBException: IO error: /var/lib/hadoop-yarn/yarn-nm-recovery/yarn-nm-state/093630.log: Read-only file system
at org.fusesource.leveldbjni.internal.NativeDB.checkStatus(NativeDB.java:200)
at org.fusesource.leveldbjni.internal.NativeDB.put(NativeDB.java:259)
at org.fusesource.leveldbjni.internal.NativeDB.put(NativeDB.java:254)
at org.fusesource.leveldbjni.internal.NativeDB.put(NativeDB.java:244)
at org.fusesource.leveldbjni.internal.JniDB.put(JniDB.java:126)
HDFS上文件Block块缺失,或者开启工作保留恢复模式时,状态存储异常情况下就会出现上述问题。将异常NodeManager下的相应状态移出即可。
[root@nodemanager_id_or_host.com yarn-nm-state]$ pwd /var/lib/hadoop-yarn/yarn-nm-recovery/yarn-nm-state [root@nodemanager_id_or_host.com yarn-nm-state]$ ls 099133.log 099135.sst 099136.sst CURRENT LOCK MANIFEST-040818 [root@nodemanager_id_or_host.com yarn-nm-state]$ rm -fr *
防火墙与代理问题
Failed to copy installation files

安装Cloudera Manager Agent失败,提示:“Failed to copy installation files.”。此时,请检查防火墙是否关闭,服务器是否配置了代理服务,如果配置了代理服务请取消。
系统依赖/组件问题
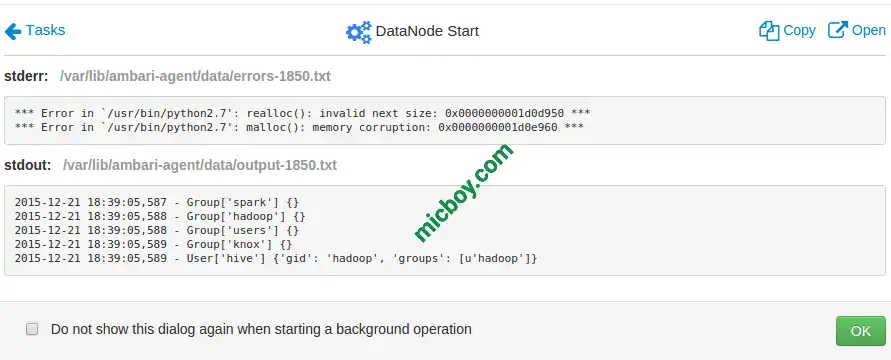
HDP malloc(): memory corruption: 0x0000000001d0e960
环境版本为Ambari 2.1.2.1+HDP 2.3,出现该问题后请尝试更新glibc,如果错误没有消失请查看日志详情。
转载请注明:麦童博客 » CDH/HDP Hadoop常见问题记录一